Scrapy网络爬虫:4.豌豆荚App安装包爬取代码实现与踩过的坑

网络爬虫
FilesPipeline典型的工作流程
Scrapy框架提供了可重用的Files Pipelines为某个特定的Item去下载文件。典型的工作流程如下所示:
在一个爬虫(Spider)里,抓取数据(Item)后,把其中文件的URL放入 file_urls 组内。
Item从爬虫内返回,进入Item Pipeline中。
当Item进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,并且优先级更高,会在其他页面被抓取前处理。Item会在这个特定的管道阶段保持"locker"的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
当文件下载完后,另一个字段(files)将被更新到结构中。这个字段是一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致Scrapy网络爬虫:3.框架组成与工作原理-组件与数据流.note。如果某个文件下载失败,将会记录下错误信息,文件也不会出现在 files 组中。
使用File Pipeline爬取豌豆荚App安装包
1. 项目需求
项目需求:爬取豌豆荚应用市场金融理财和考试学习类第一页App的安装包。
2. 豌豆荚网页分析
打开豌豆荚应用市场考试学习类应用第一页,可以看到正中央有一个应用列表,点开列表之后进入应用详情页,有一个"下载APK文件",点开即可下载相应应用。
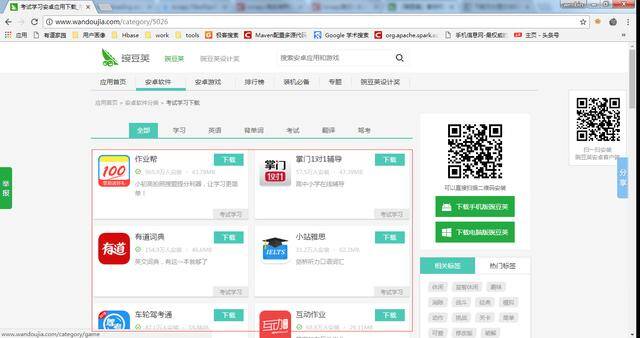
豌豆荚考试学习类应用第一页
应用详情页面
3. Scrapy爬虫项目
(1) 使用命令新建scrapy项目和爬虫
scrapy startproject filedownload
cd filedownload
start genspider AppDownloadSpider www.wandoujia.com
(2) Item定义files和file_urls字段
class AppDownloadItem(scrapy.Item):
file_urls = scrapy.Field()
files = scrapy.Field()
(3)开发Spider
爬取下载链接之后赋值给Item的file_urls字段
import scrapy
from scrapy.linkextractors import LinkExtractor
from filedownload.items import AppDownloadItem
class AppdownloadspiderSpider(scrapy.Spider):
name = 'AppDownloadSpider'
allowed_domains = ['wandoujia.com']
start_urls = ['http://www.wandoujia.com/category/5026',
'http://www.wandoujia.com/category/5023']
def parse(self, response):
# 使用LinkExtractor提取该页面应用详情链接
le = LinkExtractor(restrict_xpaths='//*[@id="j-tag-list"]/li/div[1]/a')
for link in le.extract_links(response):
yield scrapy.Request(link.url, callback=self.parse_download)
def parse_download(self, response):
download_url = response.xpath('//div[@class="qr-info"]/a/@href').extract_first()
item = AppDownloadItem()
# 保存下载链接,注意此处是列表不是字元串
item['file_urls'] = [download_url]
yield item
(4) 开启FilesPipleLine
在setting.py文件中开启FilesPipleLine
ITEM_PIPELINES = {'scrapy.pipeline.files.FilesPipeline': 1}
接着FILES_STORE 设置为一个有效的文件夹,用来存储下载的文件。 否则管道将保持禁用状态,即使你在 ITEM_PIPELINES 设置中添加了它。
FILES_STORE = './wandoujia_app'
允许重定向
MEDIA_ALLOW_REDIRECTS = True
(5) 运行爬虫,开启下载文件之旅。
scrapy crawl AppDownloadSpider -o app.json
(6)结果
安装包文件
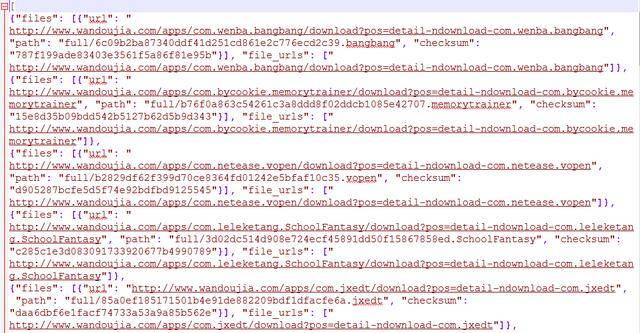
json文本
踩过的坑
(1)AttributeError: 'str' object has no attribute 'iter'
LinkExtractor的路径定位到元素而不是href属性
(2)ValueError: Missing scheme in request url: h
file_urls的类型是列表而不是字元串
(3)"File (code: 302): Error downloading file" in Scrapy Files Pipeline
允许重定向


